- 分散ファイルシステム上のファイルを読み書きしてバッチ処理を行う
ジョブ実行の流れ
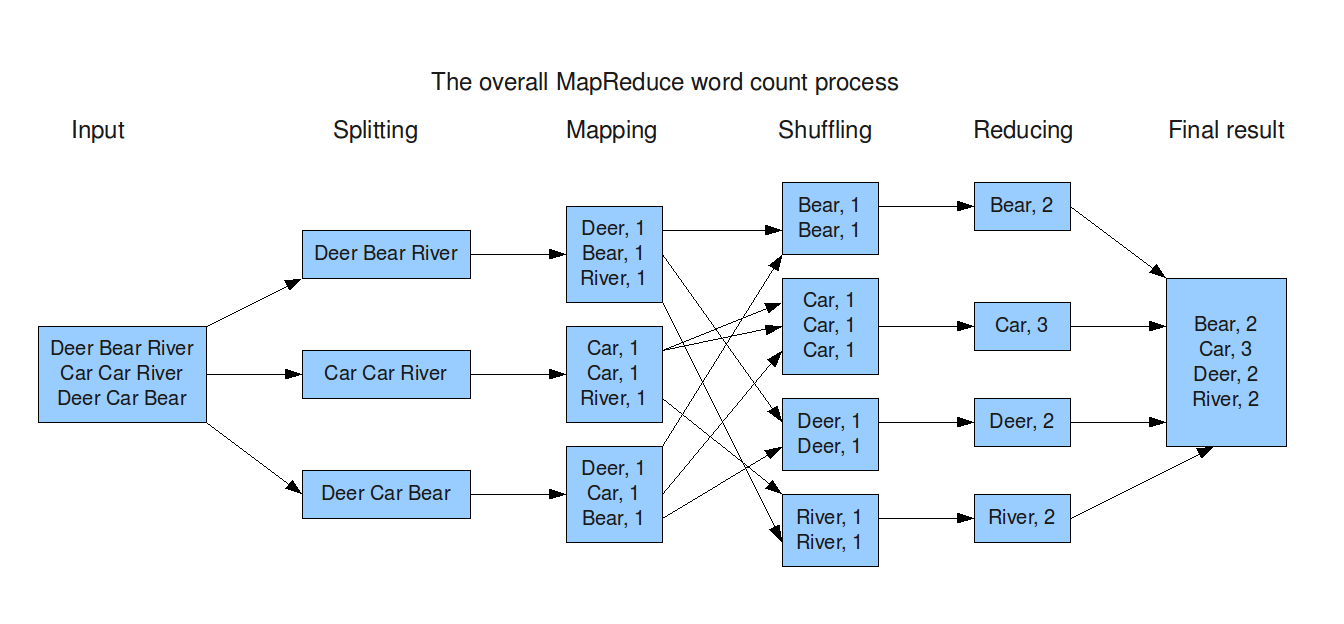 (https://imzye.com/BigData/Hadoop/MapReduce/ より)
(https://imzye.com/BigData/Hadoop/MapReduce/ より)
- 入力ファイル群を読み取り、レコードに分割する
- mapper関数を呼び出し、各入力レコードからキーと値を取り出す
- キーでキーバリューペアをソートする
- reducer関数を呼び出し、キーバリューペアに対し計算処理を行う
- mapper, reducer関数はアプリケーションプログラマが注入する
- mapper (入力データの準備): 1つの入力レコードから任意の数のキーバリューペアを生み出す
- reducer: 同じキーに属するすべての値を収集し、イテレーションを回して処理を実行し、出力レコードを生成する
Map-side join
- Mapperだけで処理を完結させる。Reducerはナシ。